














クラスター分析とは
多くの情報の中から仮説を元に、情報の関連性を明らかにする「多変量解析」の手法の一つです。クラスターは英語で「集団」「群れ」のことで、似ているものが多く集まっている様子を指す言葉です。「クラスター分析」は異なる性質のものが混ざり合っている集合体の中から、互いに類似した性質のものを集めて集団(クラスター)を作り、対象を分類する分析手法です。
マーケティングのターゲット戦略を考えるときに、生活者の意識や行動の特性により、グルーピングを行うときに用いられます。対象は人だけでなく、商品や企業、地域、イメージなどを分類する場合もあります。
分類の形式として、階層的方法と非階層的方法の2つに大きく分かれます。
階層クラスター分析
もっとも似ている対象の組み合わせを順々にクラスター化していく手法で、途中の過程が階層のようになり、最終的に樹形図(デンドログラム)が完成します。類似性が近いものから徐々にグルーピングしていくため、最初にクラスターの数を決める必要はなく、後から決めることができます。クラスターの最小数は要素全体をひとまとめにしたときの1で、最大数は対象要素の数となります。
非階層クラスター分析
階層的な構造がなく、最初にクラスター化する数を決め、決めた数のグループにサンプルを分けていく手法です。似たようなパターンのデータを持つ対象を、自動でグルーピングするアルゴリズムのことを言います。サンプルの数が多いデータを分析する際に適しています。
クラスター分析の特徴
最適なクラスター数の正解はなく、非階層クラスター分析では最初にクラスター化する数の設定をどうするかによって結果が異なる点もあります。ただ、標準化された手続きに従い、対象のデータを分類できるので、マーケティングリサーチでは市場での位置づけを目的にしたブランドの分類、イメージワードの分類、消費者のライフスタイルの分類などに用いられ、生活者サイドの視点で分類を行うことが可能です。また、新しく分類したグループごとのクロス集計から、生活者の意識や行動の特徴を深堀りし、自社のターゲット戦略に役立て、効果的なアプローチの手法を模索することができます。
多くの変数を少ない変数で説明する要約の分析手法は、他に「主成分分析」「因子分析」があります。「主成分分析」は多くの変数データを統合し、新たな指標を作り出す方法で、データの解釈がしやすくなります。例えば、食品の味の指標を甘味、塩味、酸味、辛味、コクとそれぞれ数値化し、さっぱりした美味しさと分析します。対してクラスター分析はデータの統合は行わず、グループ分けをしてグループごとの特徴を見る方法です。
「因子分析」は多くの変数データに潜む、共通因子を探り出すことが可能で、エッセンスを見ます。
クラスター分析の手順
分析を開始する際に決めなくてはならいないのは通常、次の3つです。どのように選択するかが「クラスター分析」のポイントになります。
1 分析の種類
階層的方法か非階層的方法のどちらかを選択します。
2 分類の基準となる対象の類似度や対象間の距離
距離を算出する方法としてユークリッド距離(2点間の直接距離)、マハラノビス距離(テーマ群からの距離)などがあります。
3 階層的方法のクラスター間での距離の測定法
ウォード法、群平均法、最短距離法、最長距離法などがあります。ユークリッド距離を使用して、距離が近いものをグルーピングし、グループ化を繰り返します。最終的には樹木の幹が形作られるような樹形図が出来上がります。その後、複数のグループ分けをして各グループの特徴を見たり、クロス集計を行い、意識や行動の深堀りを行ったりします。
クラスター分析事例
クラスター分析は、アンケート調査の質問項目(カテゴリー)や回答者を回答の類似性から分類しグルーピングする手法です。回答のされ方が類似している質問項目(カテゴリー)をグルーピングする方法を「変数クラスター分析」、回答の仕方が類似している回答者をグルーピングする方法を「サンプルクラスター分析」と呼びます。分析に際しては、回答サンプルごとのアンケートの回答データ(ロウデータ)から質問項目間、回答者間の距離を計算し、距離が近い(短い)ものを集めてグルーピングします。
以下は、ファッションに対する志向を10人の人にアンケートにより回答してもらった回答データです。
【ファッションに対する志向(回答データ)】
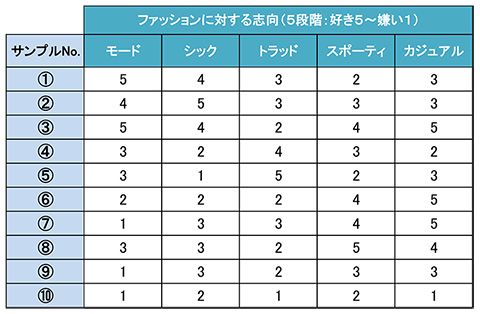
このデータから回答者をグルーピングする「サンプルクラスター分析」の手順をみてみましょう。クラスター分析は回答者間の距離を計算し、距離が近い(短い)もの同士を集めてグループ化する分析手法ですので、まずは距離の計算を行います。
距離を算出する方法はいくつかありますが、最も一般的なものが「ユークリッド距離」の測定で、以下のような公式で求められます。
下記のような回答データから「No.①と②の回答者間の距離(d)」の2乗をd²とする。
d²=(x₁-y₁)²+(x₂-y₂)²+(x₃-y₃)²+(x₄-y₄)²+(x₅-y₅)²
ここから、距離d=√d²
【回答データ】

前掲の回答データを用いて10人の回答者間の距離を計算すると以下のような結果になります。
【回答者間の距離】
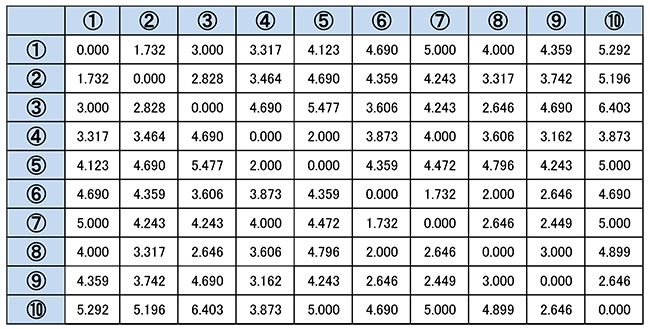
上記のサンプル間の距離からみると一番距離が近いのは「①と②」及び「⑥と⑦」です。まずは、この組み合わせをそれぞれ1つのグループと考えて[①,②]、[⑥,⑦]とします。近いとは言ってもグループ[①,②]及び[⑥,⑦]には、それぞれ2つの点が存在するので、このグループを代表する点(値)を1つ定めます。これを「合併後の距離計算」と言い、最短距離法、最長距離法、群平均法、重心法、ウォード法などいくつかの方法があります。これによって定められた新たなサンプルグループ[①,②]及び[⑥,⑦]の数値により他のサンプルとの距離を再計算し、最も近いサンプル同士のグループ化を繰り返し行っていきます。
クラスター分析では、グループ化された結果を樹形図(デンドログラム)として表します。樹形図は距離の近いサンプル同士を矩形で結んでいきます。再計算を繰り返して合併されていくグループ同士も距離の近いものの順に並べられ矩形で結んでいき、樹の根から幹が形作られるように上方に向かって一つの幹になるまで計算を繰り返していきます。矩形の高さは結ばれたサンプル(グループ)間の距離の近さに比例して示します。前掲のファッション志向によるサンプルクラスター分析の結果は以下のような樹形図となります。
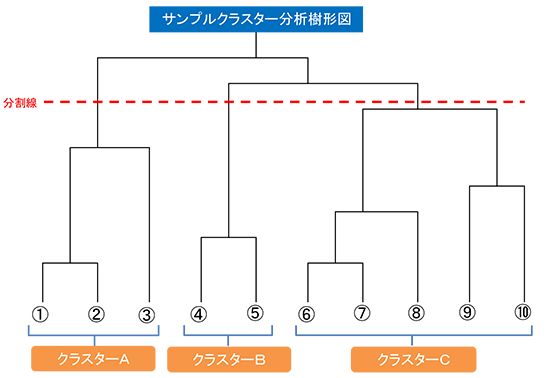 この結果からサンプル全体を3つのグループに分けたいと思えば、3つの交点ができるよう横に分割線を引きます。この分割線の交点より下にあるサンプルが、そのグループに属するサンプルとなります。グループ数については、それぞれのグループの特徴が出るように分析者が決めます。一度3つのグループと見当をつけて各グループの特徴をみた結果により、再度4つに分けて分析を行うなど分析の精度を高めるための試行錯誤が必要になる場合もあります。
この結果からサンプル全体を3つのグループに分けたいと思えば、3つの交点ができるよう横に分割線を引きます。この分割線の交点より下にあるサンプルが、そのグループに属するサンプルとなります。グループ数については、それぞれのグループの特徴が出るように分析者が決めます。一度3つのグループと見当をつけて各グループの特徴をみた結果により、再度4つに分けて分析を行うなど分析の精度を高めるための試行錯誤が必要になる場合もあります。
クラスター分析によって分けられたグループを「クラスター(グループ)」と呼びます。今回の分析で得られた3つのクラスターの特徴をみるためにクラスターを表側としたクロス集計分析を改めて行い、クラスターに名前をつけます。各クラスターと分析の元となったファッション志向の結果をクロス集計したら下表のようになりました。本来は他の意識や行動に関する質問項目、属性項目等ともクロスして特徴を細かくみて、ネーミングやクラスター分析の精度を確認します。
【クラスタークロス集計表】
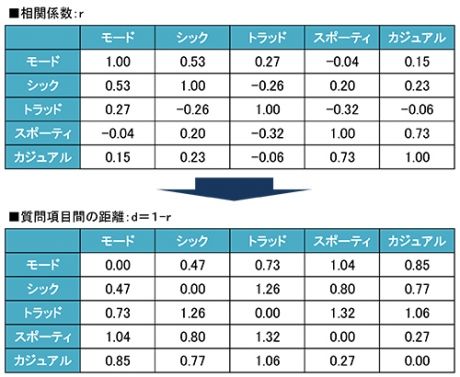
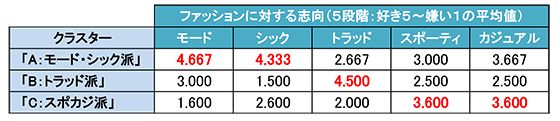 3つのクラスターをA,B,Cとすると、クラスターAは「モード」で「シック」なファッションに対する志向が強いので「モード・シック派」としました。同様にBは「トラッド派」、Cは「スポカジ派」と名づけました。
3つのクラスターをA,B,Cとすると、クラスターAは「モード」で「シック」なファッションに対する志向が強いので「モード・シック派」としました。同様にBは「トラッド派」、Cは「スポカジ派」と名づけました。
変数クラスター分析については、変数間の距離の算出方法がサンプルクラスター分析とは異なり、変数間の相関係数( r )によって求められます。「変数間の距離d=1-r」の公式から、相関係数が大きく(関係性が強い)なればdは小さく(距離が近く)なります。変数間の距離が算出されれば、解析の手順はサンプルクラスター分析と同様です。
クラスター分析 応用事例
ある商品のターゲット層を「美容に対する意識」と「ワークライフバランス意識」でクラスター分析を行いました。分析の結果、「“ストイック”に仕事タイプ」「“何でも欲しがる”欲張りタイプ」「プライベート“のびのび充実”タイプ」「無関心“マイペース”タイプ」の4つのクラスターに分けられました。以下のようなポジショニングマップで表すと、各クラスターのボリュームとグルーピングの軸に対する位置関係が一目でみてとれます。
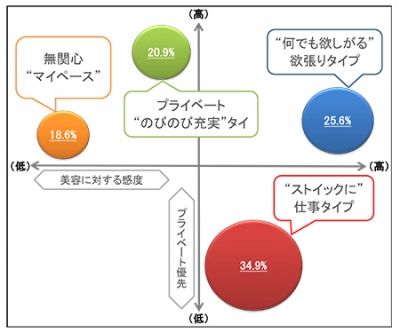
クラスターのボリュームからすると「仕事タイプ」が狙い目のように思われますが、下記のようなクロス集計分析を行うことで、対象商品に対する購入意向が強い「欲張りタイプ」が注目すべきターゲットであることがわかります。また、接触媒体への傾向から媒体Dによるアプローチが有効であることも明らかになりました。

Related Column/ 関連コラム
-

クラスター分析で見えてくるシングルソース活用の幅
-
女性を対象としたマーケティングはこまめな細分化が鍵
-
変遷する市場のカスタマー像をシングルソースデータベースから発掘!
-
多変量解析の活用